GPU
La componente GPU del chip Llano, nome in codice “Sumo”, riprende molte delle caratteristiche della famiglia di GPU “Redwood” di AMD, implementata nelle serie Radeon 5500 e Radeon 5600.
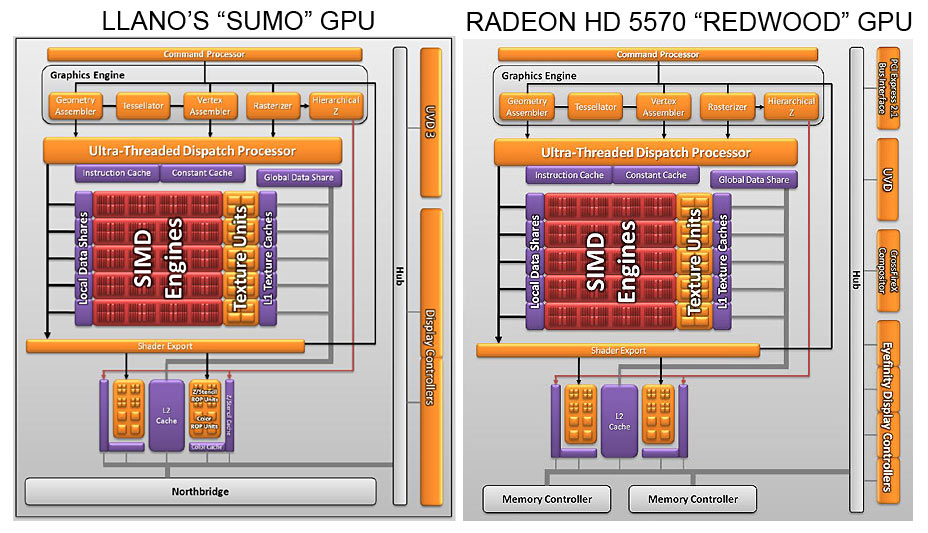
Dal confronto delle due immagini, si nota che non è cambiato molto tra “Sumo” e “Redwood” nel cuore di elaborazione. Abbiamo i SIMD engines, 5 in totale, ognuno composto da 16 thread processor e 4 texture unit.
Ogni thread processor è composto da una unità con architettura VLIW 5, capace di eseguire fino a 5 operazioni per ciclo di clock, dando così un totale di 400 operazioni di calcolo e 20 operazioni su texture per ogni ciclo di clock. In più sono presenti due render back-end, ciascuno capace di 4 operazioni raster (ROP) per ciclo.
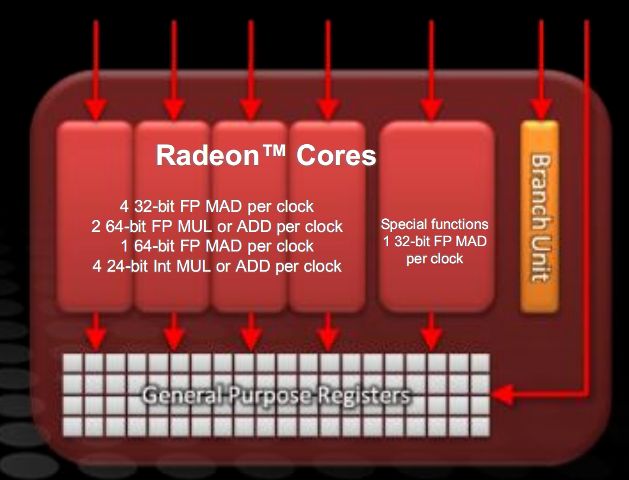
In particolare in figura possiamo notare la struttura dell’unità VLIW 5 delle architetture grafiche AMD. L’unità delle funzioni speciali può eseguire una moltiplicazione e addizione (MAD) in virgola mobile (FP) per ciclo, oppure un passo di elaborazione di una funzione speciale (come funzioni trascendenti, esponenziali eccetera) per ciclo.
Le restanti 4 unità di esecuzione possono eseguire 4 FP MAD a 32 bit, oppure una qualsiasi combinazione di 2 tra addizioni e moltiplicazioni FP a 64 bit, una FP MAD a 64 bit oppure una qualsiasi combinazione di 4 tra addizioni e moltiplicazioni intere a 24 bit.
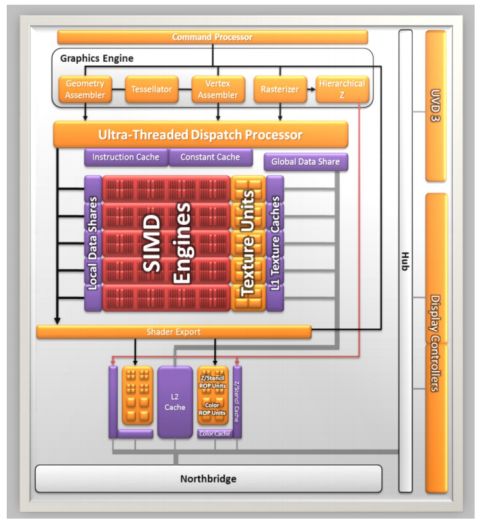
Dal confronto con “Redwood”, si può vedere che mentre quest’ultimo ha un controller RAM a 128 bit per memorie DDR3 o GDDR5, UVD di seconda generazione e 4 controller per il display, capaci anche di un certo livello di supporto alla tecnologia Eyefinity, “Sumo” ha un collegamento diretto al controller RAM DDR3 a 128 bit presente sul North Bridge, UVD di terza generazione e 2 controller dedicati per il display. Se si rinuncia alla interfaccia PCI Express x16, è possibile configurare altre uscite video, per consentire l’implementazione della tecnologia EyeFinity.
L’integrazione on die della GPU e il collegamento diretto al North Bridge hanno giovato alla GPU, compensando in parte il fatto di avere un controller DDR3 condiviso con la CPU.
La GPU, infatti, è collegata al resto del sistema da ben 3 BUS.
Il primo è il collegamento “Garlic”, che è un collegamento diretto, senza controllo di coerenza, a bassa latenza, a 128 bit, tra GPU e controller RAM, arbitrato dal solo Front-End del controller RAM, che gli garantisce alta priorità e bassa latenza. La frequenza a cui opera tale collegamento dovrebbe essere presumibilmente quella del Northbridge, che dovrebbe essere intorno ai 2GHz, visto che AMD dichiara una banda superiore ai 30GB/s verso il controller RAM, che con 2 miliardi di trasferimenti al secondo si superano di poco. E’ un miglioramento rispetto ai 64 bit del BUS per la GPU di Ontario/Zacate.
Il secondo è il collegamento “Onion”, che interfaccia la GPU con il sistema coerente, composto dalla memoria, dalla CPU e le loro cache, che ubbidisce al protocollo MOESI. Questo collegamento diretto e a bassa latenza è un notevole passo avanti. Con una GPU esterna, in particolare con un IGP, si doveva passare per il bus di collegamento tra scheda grafica (o North Bridge nel caso di IGP) e CPU, attendere che il relativo North Bridge integrato controllasse le cache e eventualmente la RAM e rispedisse i risultati. Ora i due controlli possono essere fatti indipendentemente e in parallelo (attraverso entrambe le interfacce Onion e Garlic) e con una latenza molto più bassa.
Il terzo collegamento è quello diretto tra GPU e l’unità GIO, per l’accesso al controller PCI Express, per un eventuale CrossFire con schede discrete e per la gestione delle uscite video. La stessa sorte non tocca ai core della CPU che, per accedere al GIO, devono passare per il North Bridge e subirne le relative latenze e attese.
Un altro grande vantaggio di una GPU integrata nello stesso chip della CPU è relativo allo scambio di dati in memoria. Con le schede grafiche convenzionali, per effettuare il rendering di una scena, devono essere usate varie strutture dati: griglie di vertici (mesh), informazioni di colore e illuminazione e texture mapping, per la colorazione finale.
Queste informazioni sono create dal software 3D in memoria e sono passate al driver della scheda grafica. Poiché i processi lavorano con la memoria virtuale, è possibile che per accedervi il driver debba addirittura caricarli dal disco. In ogni caso devono essere trasferiti nella memoria interna della scheda video, tramite il bus PCI Express.
Analogamente succede per i calcoli GPGPU, dove, in più, i dati devono percorrere anche il tragitto inverso, per caricare in memoria principale i risultati del calcolo.
Tutto questo con una APU non è più necessario. L’APU Llano implementa 2 tecniche per velocizzare queste operazioni.
La prima si chiama Zero Copy e consente di non copiare più i dati, ma dire semplicemente alla GPU dove sono e poterli utilizzare direttamente. Ciò è possibile perché la GPU può accedere direttamente alla RAM. Ma la memoria virtuale consente di spostare i dati dentro e fuori dalla memoria e riallocarli a piacimento. Llano non implementa ancora un gestore della memoria virtuale sofisticato per consentire di sfruttare uno spazio di memoria unificato. Le successive architetture lo implementeranno e renderanno la GPU un vero e proprio coprocessore vettoriale, un po’ come le prime FPU apparse anni fa.
Per evitare problemi, entra in scena la seconda tecnologia: Pin in Place. Questa consiste nel bloccare le strutture dati in un’area specifica di memoria, affinché la GPU possa ritrovarle e accedervi in sicurezza e affinché non sia portata fuori memoria, sul disco rigido, allungandone i tempi di accesso.
In realtà la CPU usa la classica tecnica di memoria virtuale, chiamata demand paging, gestita dal SO, mentre la GPU ha la paginazione gestita dal driver video, di concerto ovviamente con il sistema operativo per implementare le due tecnologie di cui sopra. Il Pin in Place serve proprio a questo: il driver grafico blocca in memoria delle pagine per i suoi usi, tramite i normali meccanismi offerti dal sistema operativo, e poi mappa tali pagine nella memoria virtuale della GPU in modo che essa vi possa accedere.
La GPU gestisce la memoria con una logica più rilassata rispetto alle CPU x86, consentendo un riordinamento degli accessi più spinto, che portano migliori prestazioni. La GPU deve accedere alla memoria con le regole più restrittive della CPU solo quando accede alla memoria Pinned, per evitare di interferire con la CPU e la CPU invece si appoggia al driver per sincronizzarsi con al GPU.
Veniamo ora ai dettagli sull’interscambio di informazioni tra CPU e GPU.
La GPU accede alla memoria in modalità interleaved, ossia blocchi di dati consecutivi sono alternati nei canali RAM, per ottimizzare la banda di accesso, mentre la CPU accede alla memoria tipicamente in modalità non interlacciata o comunque in modalità ottimizzata per la latenza.
Gli accessi alla RAM da parte della CPU seguono il classico approccio coerente con il protocollo MOESI, per la RAM normale. La memoria riservata alla GPU viene vista come memoria non cacheabile e con write combining attivato. Scritture della CPU verso tale memoria seguono il classico protocollo per tali accessi e i dati transitano dal bus “Onion” verso la GPU, che poi li scrive in memoria, ottenendo in totale una velocità comunque superiore a quella ottenuta tramite il PCIExpress (si parla di circa 8GB/s). Letture della memoria GPU da parte della CPU sono piuttosto lente sia perché la memoria è uncacheable, e quindi tramite il bus “Onion” si deve forzare la scrittura di tutti i dati modificati dalla GPU in RAM, sia perché è possibile avere solo una di queste transazioni in atto in ogni istante.
La GPU accede alla memoria RAM riservata alla GPU in modalità non coerente, e perciò non affetta da tutto l’overhead che la coerenza si porta appresso, e in modalità interleaved sui canali di memoria. Tutto questo lo fa tramite il BUS “Garlic”, che ha alta priorità ed ha un collegamento diretto con il controller della memoria. Il driver comanda alla GPU di leggere la memoria non riservata ad essa, quando si devono prelevare dati esterni, come mesh, texture o dati per il GPGPU. Comanda scritture su tale memoria quando si devono passare i risultati di un calcolo GPGPU oppure per copiare il frame buffer in RAM per elaborazioni varie. La memoria non riservata alla GPU è gestita o in modalità uncached, o con il protocollo di coerenza MOESI, implementato dai core della CPU. Se la memoria è non cacheable, allora le cache non devono essere controllate, così non è necessario usare il bus “Onion” per accedere al dominio coerente. Si può usare il bus “Garlic”, ma la memoria deve essere bloccata (pinned), perché la GPU non implementa ancora in hardware la memoria virtuale in modalità compatibile con i core x86, in più essa in genere non è acceduta in modalità interleaved, perciò è un po’ più lenta. Ma non quanto l’accesso alla memoria cached, che richiede di passare per il bus “Onion”, essere accodato nella coda IFQ e richiede il controllo delle cache delle CPU. Anche qui la memoria deve essere bloccata, poiché la GPU lavora con indirizzi fisici.
Quando sarà implementata nelle GPU di future generazioni la memoria virtuale in modo identico a quello delle CPU x86, allora si potrà parlare di spazio di memoria unificato e tali accorgimenti software non saranno più necessari. Sarebbe persino possibile paginare su disco la memoria grafica, se implementassero lo scambio di segnali di page fault dalla GPU alle CPU.
Queste tecnologie possono, in casi eccezionali, far avere una velocità superiore a quella di una scheda video discreta. Ma la condivisione del controller RAM rende comunque la GPU integrata un po’ più lenta di una sua discreta equivalente.
La GPU, a differenza di quella implementata nel Sandy bridge, supporta pienamente le DirectX 11 e il filtraggio anisotropico indipendente dall’angolo.
Altre caratteristiche supportate sono l’OpenGL 4.1, l’OpenCL 1.1 e le tecniche di anti-aliasing MSAA, SSAA e MLAA.

In figura è possibile vedere un diagramma a blocchi delle varie generazioni di UVD. La terza generazione, implementata in Llano, è in grado di accelerare in hardware i codec MPEG-4 Part 2 (di cui fanno parte anche i codec DivX e Xvid), MPEG-2, e il codec Multi-View (MVC) utilizzato per l’accelerazione dei contenuti Blu-ray 3D, che possono essere visualizzati tramite la porta HDMI 1.4a di cui Llano è dotata.
La decodifica è fatta tutta nel blocco UVD3, così il resto della GPU può essere messa in risparmio energetico avanzato (power gating) e risparmiare molta energia.
Dual Graphics
Ultimo capitolo per quanto riguarda la GPU di Llano è la tecnologia Dual Graphics. Essa consente di accoppiare, come la tecnologia CrossFire, schede video per incrementare le prestazioni. Ma a differenza di quest’ultima, consente di bilanciare il carico tra le GPU, tenendo conto delle differenze di potenza.
Il meccanismo non è perfetto, essendo dipendente molto dalla qualità e maturità dei driver e inoltre funziona al meglio con applicazioni DirectX 10 e 11. Con applicazioni DirectX 9, le prestazioni sono pari a quelle della scheda più lenta.
Come abbiamo visto in precedenza, le tecnologie CrossFire/DualGraphics ed EyeFinity sono mutualmente esclusive a meno di non accontentarsi di un numero inferiore di interfacce per i display: il controller PCI Express x16 è suddivisibile in due controller x8 di cui uno può essere utilizzato per il CrossFire e uno per i display aggiuntivi. Naturalmente per ottenere il massimo numero di interfacce video è necessario rinunciare al supporto CrossFire, così come per ottenere un supporto CrossFire pieno, con interfaccia x16 o con due interfacce x8 per effettuare un triplo CrossFire è necessario rinunciare al supporto EyeFinity.
Nel caso in cui la differenza di prestazione tra la scheda o le schede discrete abbinate alla GPU integrata siano notevoli, l’incremento di prestazioni rispetto solo uso della scheda discreta è modesto.
In compenso, però, AMD ha implementato i driver in modo da poter indirizzare le chiamate OpenCL 1.1 alla GPU integrata senza appesantire le GPU discrete, qualora queste stiano elaborando un carico 3D gravoso.